Una de las principales preocupaciones de las entidades financieras hoy en día es la política comercial que deben seguir con sus clientes en las retiradas de efectivo en cajeros a partir del Real Decreto-ley 11/2015, de 2 de octubre, que regula las comisiones por la retirada de efectivo en los cajeros automáticos.
Esta ley surgió de la necesidad por parte del Gobierno de regular lo que se empezó a conocer como “la guerra de los cajeros” y que fue iniciada por CaixaBank cobrando dos euros a los no clientes en marzo de 2015.
El siguiente gráfico del periódico El País, nos ayuda a entender esta “famosa” ley en el sector bancario de los últimos tiempos:
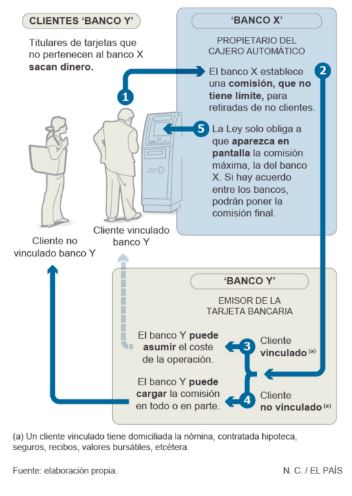
Con esta nueva situación en el sector surge la necesidad por parte de las entidades financieras de una segmentación avanzada de sus clientes para diferenciar las tarifas comerciales a aplicar en cada caso. En un primer momento, por lo que han optado la mayoría de las entidades es por aplicar los mismos beneficios a todos sus clientes (por ejemplo, 5 retiradas en cajeros distintos a los propios gratis al mes). Estas políticas generalizadas nunca son buenas, tanto para la entidad como para los clientes, que cada uno se comporta de manera diferente.
Con esta situación en la calle, y gracias a los datos que EURO 6000 facilitó a Jose Ramón Cajide (Digital & Big Data Analyst en El Arte de Medir y ahora Data Scientist) y Marta Cámara (Data Scientist en Euro 6000) quienes están detrás de este proyecto, se les ocurrió tratar de hacer una segmentación de clientes en función de su comportamiento en las retiradas de efectivo en cajeros a partir de enero de este año (es decir, el momento de entrada en vigor de la nueva regulación sobre comisiones en cajeros). La incorporación de nuevas fuentes de datos a las segmentaciones tradicionales posibilita la obtención de una visión y un entendimiento más completos de sus clientes. Conocer mejor a los clientes permite realizar un targeting más ajustado, y esto se traduce en mayor eficiencia y rendimiento de las acciones comerciales.
Hoy, juntos, nos cuentan cómo han desarrollado el proyecto, cómo han aplicado lo aprendido en el maestría de Data Science y lo comparten con nosotros:
Desde un principio los dos teníamos claro que queríamos aplicar a nuestro proyecto todo aquello que habíamos aprendido durante la maestría, tanto en lo que respecta al empleo de una metodología para la gestión del proyecto como en la combinación de parte de las herramientas y modelos.
Comenzamos tratando de entender el ámbito, conocer el negocio en el que íbamos a centrar nuestro proyecto. Esta es una de las cosas que te enseña Israel Herraiz (director dla maestría) el primer día de clase y es un factor crítico para alcanzar el éxito en cualquier proyecto de data science.
Esto te facilita el identificar el enfoque analítico a seguir, los métodos estadísticos o de aprendizaje automático (machine learning) que nos ayudarían a dar respuesta a la pregunta de negocio que nos planteamos inicialmente.
A partir de aquí comenzamos por obtener los de datos para el proyecto. Fue un proceso que se repitió hasta que conseguimos la información que necesitábamos para ser analizada.
Comenzamos entonces la parte más laboriosa en la que tratamos los datos y realizamos un minucioso análisis exploratorio de los mismos. Aunque esta parte fue ejecutada en su mayor parte usando lenguaje R, no dejamos de utilizar los conocimientos aprendidos para el manejo de datos mediante la línea de comandos de Linux (bash) así como de alguna librería en Python.
Seguimos con un proceso de transformación de los datos, tomando ciertas variables existentes y generando nuevas a partir de las ya existentes para posteriormente realizar aquellos test estadísticos que nos informaban de la variables que debíamos considerar y cuáles excluir.
A continuación iniciamos la fase de modelado, es decir, aquella en la que se trata de dar forma a los datos Es la fase en la que tratamos de encontrar tras realizar pruebas con nuestros equipos y dado el volumen de datos que teníamos y la complejidad de los cálculos, optamos por utilizar el cluster al que teníamos acceso. Esta fase suponía un desafío para nosotros pero nos sirvió para aprender a desarrollar una aplicación en Python haciendo uso de la api para Spark (Pyspark) y a implementar un algoritmo de aprendizaje no supervisado sobre un entorno en el que los datos se encontraban distribuidos en varios nodos de servidores Hadoop.
Una vez evaluado el modelo y finalizamos con la visualización del resultado. Durante la maestría aprendimos a realizar potentes visualizaciones con R, D3.js, Tableau e incluso Python. Las clases de Tableau nos vinieron genial y pudimos comunicar mediante un Storytelling realizado con Tableu el resultado final de nuestro proyecto.
La parte más difícil sin duda fue el tener que trabajar con un gran volumen de datos. Generalmente estamos acostumbrados a trabajar con ficheros de datos pequeños, pero cuando te enfrentas a más de cuatro gigabytes de datos sobre los que tienes que hacer agrupaciones, cálculos complejos y aplicar algoritmos, es entonces cuando tienes que hacer uso de tecnologías más avanzadas que nos obligaban a asumir nuevos retos, como tener que programar sobre datos de muestra y ejecutar el análisis sobre el conjunto final de datos sobre una arquitectura Big Data.
Por otra parte, siempre hemos valorado que una maestría te obligue a la realización de un proyecto final. Es la mejor forma de poner en práctica lo aprendido y afianzar conocimientos. No sólo aplicas lo aprendido en clase sino que tienes que investigar y buscar soluciones a tus problemas.
Por ejemplo, utilizamos varias librerías de manipulación de datos, aplicamos diferentes algoritmos y experimentamos con diversos entornos como Cloudera o Hortonworks lo que nos ayudó a entender la complejidad que entraña cualquier proyecto de data science en cuanto trabajas con grandes volúmenes de datos.
Y no olvidemos el lado humano. Los proyectos dan lugar a muchas conversaciones que sirven para afianzar relaciones con todos los compañeros dla maestría y a echarnos unas risas.
Ahora que la maestría ha finalizado, hemos podido aplicar en nuestros trabajos lo aprendido.
En mi caso concreto – José Ramón – hace tres años que trabajo como analista en El Arte de Medir y desde el primer día de clase he podido aportar soluciones basadas en los conocimientos adquiridos. Actualmente disfruto enfrentándome a nuevos retos transformando datos en conocimiento mediante técnicas que hasta entonces eran desconocidas.
Cada análisis supone un nuevo reto al que no me importa enfrentarme gracias a la amplia base de conocimientos adquirida en la maestría.
Han sido muchas horas de clase, en las que hemos aprendido sobre linux, lenguaje SQL, python, R, modelos estadísticos y algoritmos de machine learning, álgebra matricial, visualización y todo impartido por un equipo de profesores high level, tanto en lo profesional como en lo personal.
Toca ahora repasar, aplicar los conocimientos adquiridos y seguir aprendiendo.
Si quieres acceder a todo el repositorio del proyecto de Jose Ramón y Marta y ver cómo han desarrollado cada parte de tu TFM para el maestría de Data Science, puedes hacerlo desde aquí.
El artículo A Data Science project in Banking Domain: TFM de José Ramón Cajide y Marta Cámara fue escrito el 6 de September de 2016 y actualizado por última vez el 2 de June de 2026 y guardado bajo la categoría Data Science. Puedes encontrar el post en el que hablamos sobre .
Nuestros cursos
Maestría en Data Science
Domina las mejores técnicas de análisis de datos
Master
8 meses
Primavera
Maestría en Product Manager
Titulación conjunta con:

Master
8 meses
Otoño
Descrubre nuestros cursos

02 · 06 · 2026
Big data en el fútbol: aplicaciones, herramientas y el futuro del análisis deportivo
El análisis de datos está presente en cada vez más campos diferentes, también en el deporte. Te contamos cómo se aplica el Big Data cuando hablamos de rendimiento deportivo ya que puede usarse tanto en clubes profesionales como en preparación física profesional. Te damos las claves que necesitas para saber cómo puedes sacarle el máximo […]

15 · 04 · 2026
Data Lake: Qué es, Arquitectura y Clave para el Big Data
Las empresas en la actualidad gestionan un gran volumen de datos, lo que hace imprescindible poder comprender cómo lo hacen. Te contamos por qué el Data Lake es un tecnología imprescindible cuando hablamos de estrategia de análisis y cómo se ha convertido en fundamental en la actualidad. Definiendo el data lake: más allá del almacenamiento […]

02 · 06 · 2026
Web Scraping: guía definitiva de extracción de datos web
A la hora de analizar datos es fundamental conocer una serie de técnicas y sobre todo, entender cómo se recopilan los datos en Internet. Te contamos qué es el Web Scraping y por qué motivo esta técnica se ha convertido en una habilidad imprescindible para los analistas de datos. ¿Qué es el web scraping y […]

02 · 06 · 2026
LightGBM: el framework que ofrece potencia y velocidad en Ciencia de Datos y Aprendizaje Automático
LightGBM es un algoritmo de boosting basado en árboles de decisión que destaca por su velocidad, eficiencia y capacidad para trabajar con un gran volumen de datos. Se ha convertido en una herramienta fundamental dentro del stack de cualquier profesional, desde el científico hasta el analista de datos, que trabaja con modelos predictivos. Por ello, […]